원글 링크: https://heisenberg.kr/high-k-nand/
1분 요약
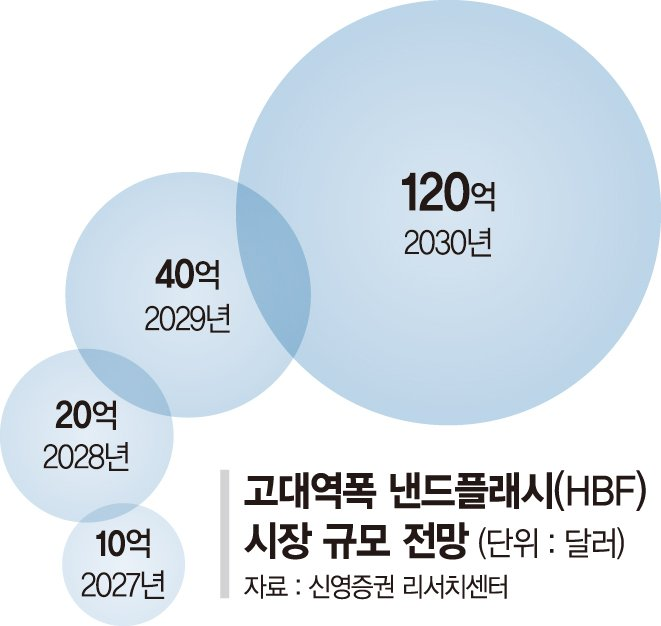
지금 AI 인프라에서 가장 큰 문제는 메모리 비용과 구조다. 대형 모델을 추론에 쓰려면 수천억~수조 개 파라미터를 계속 불러와야 하는데, 이걸 HBM 만으로 해결할 수는 없다. 이 문제를 해결하려고 나온 것이 HBF다. 기존처럼 멀리 있는 저장장치에서 데이터를 가져오는 방식이 아니라, 연산 장치 가까이에 대용량 데이터를 붙여 두는 구조다. 속도는 HBM보다는 느리지만, SSD보다는 훨씬 빠르고, 무엇보다 같은 비용으로 훨씬 많은 데이터를 담을 수 있다. 덕분에 자주 쓰는 데이터는 멀리서 가져오지 않아도 되고, 비싼 메모리를 무한정 늘리지 않아도 된다. AI 모델이 커질수록 연산 성능 뿐 아니라 메모리 종류와 배치가 중요해 질 것이다. 그리고 HBF는 가장 현실적인 보완재다.
Chapter 1. 나의 생각
HBM에 대한 과거 학계의 반응
2010년대 중반, HBM이 처음 학회에서 이름이 퍼져 나갈 때가 기억이 나는데요.
당시 수많은 ‘자칭’ 전문가들은 코웃음을 쳤습니다. “누가 메모리에 구멍을 뚫어 칩을 쌓는 미친 짓을 하겠나?”, “그 비용을 감당할 서버가 어디 있나?” 라고 말입니다. 내로라하는 교수님들조차 그런 말씀을 많이 하셨던 것이 생생히 기억납니다.
하지만 저는 당시 운이 좋았습니다. HBM은 모르겠고 1등인 삼성전자는 딱히 관심이 없었습니다. 그래서 엔비디아와 하이닉스에 투자했었습니다. 저는 이공계 종사자지만, 이렇게 글을 쓰는 것에서도 아실 수 있듯 돈 버는 것에 관심이 많습니다. 하지만 대부분 연구자들은 희한하게 아는 건 많은 데 돈 버는 재주는 없습니다. 저는 이게 너무 알면 알수록 오히려 보수적이게 되고, 자신들이 맞이한 문제점이 너무 어렵다는 걸 알기 때문에 사업가스러운 도전의식이 부족하기 때문이 아닌가 조심스럽게 생각을 해봅니다.

다만 저는 애시당초 어떻게 하면 돈을 벌 수 있을지 관심이 많았고, HBM은 소위 ‘cool’ 해보였어요. 그런데 당시 삼성전자는 1등이었으니, 2등인 하이닉스에 투자했고 이들을 쓰려면 병렬 처리를 주로하는 GPU 기업에 투자해야 겠다고 생각했습니다. 결과는 여러분이 아는 그대로입니다.
교수님들은 기술의 비용만 보았고, 저는 연산 장치가 겪게 될 목마름을 보았다고 자신있게 생각합니다. AI가 폭발적으로 발전하는 지금 단계에서, 단기적으로는 SK하이닉스와 삼성전자의 부흥은 이어질 것입니다. 하지만, 메모리 반도체를 비롯한 하드웨어가 안정적으로 자리 잡은 후 AI 데이터 경쟁에서 구글, 애플, 메타를 이길 기업은 없을 것입니다.
그리고 저는 지금, HBF(High Bandwidth Flash)를 두고 비슷한 일이 벌어지고 있다고 생각합니다. 사람들은 낸드 플래시는 저장 장치일 뿐이야, 속도가 느리다고 단정 짓습니다. 하지만 지금 AI 시장의 본질을 꿰뚫어 보십시오. 학습(Training)의 시대가 지나고 추론(Inference)의 시대가 오고 있습니다.

수조 개의 파라미터를 가진 거대 언어 모델(LLM)을 실시간으로 돌리기 위해, HBM은 너무 비싸고 용량이 부족하며, SSD는 너무 느립니다. 이 거대한 간극, 즉 메모리 장벽(Memory Wall)을 메울 유일한 대안은 HBF뿐입니다.[1]
Chapter 2: 배경 및 원리
AI 시대의 삼중고(Trilemma)와 잃어버린 고리
우리가 흔히 사용하는 컴퓨터 구조를 인간의 뇌에 비유해 봅시다. GPU와 NPU는 데이터를 처리하는 뇌세포(뉴런)입니다. 그리고 HBM은 뇌세포 바로 옆에서 정보를 즉시 제공하는 해마(단기 기억)와 같습니다. 반면, SSD는 저 멀리 있는 도서관 서고입니다.
과거에는 도서관에서 책을 꺼내오는 속도(SSD)만으로도 충분했습니다. 하지만 AI라는 괴물이 등장하면서 상황이 바뀌었습니다. 이 괴물은 초당 수천 권의 책을 읽어야 하는데, 해마(HBM)는 용량이 턱없이 부족하고, 도서관(SSD)은 너무 멉니다. 이것이 바로 현재 데이터 센터가 직면한 속도, 용량, 전력 효율의 삼중고(Trilemma)입니다.
HBM은 TSV 기술로 대역폭 문제를 해결했지만, 근본적으로 DRAM 소자이기에 전원이 꺼지면 데이터가 날아가고(휘발성), 무엇보다 비트(bit)당 비용이 너무 비쌉니다. 반면, SSD는 용량 대비 가격은 저렴하지만, PCIe 인터페이스(메인보드와 SSD, 그래픽카드와 같은 핵심 부품을 연결하는 물리적 규격)라는 좁은 문을 통과해야 하므로 GPU가 요구하는 광속의 데이터를 감당하지 못합니다.[2]
이때 등장한 HBF(High Bandwidth Flash)는 뇌세포 바로 옆에 거대한 개인 서재를 짓는 것과 같습니다. 기존의 SSD보다 수십 배 빠르고, HBM보다 10배 이상 큰 용량을 제공하여, AI 모델의 가중치(Weight)나 KV Cache와 같은 데이터를 저장하는 Near Memory 역할을 수행합니다. 이는 HBM의 용량 한계와 SSD의 속도 한계 사이, 즉 Memory Wall의 간극을 메우기 위해 탄생한 필연적인 기술적 진화입니다.[3]
HBF 아키텍처: HBM의 유전자를 이식받은 낸드
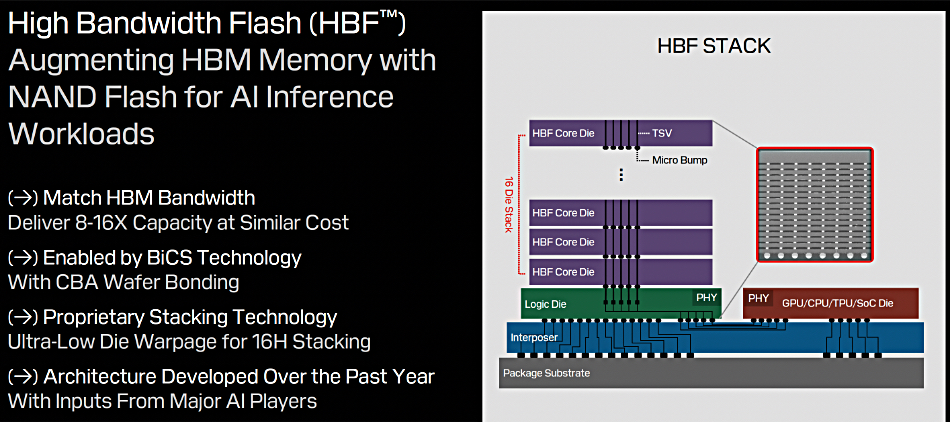
HBF의 작동 원리는, 낸드 플래시를 HBM처럼 쌓는다는 겁니다. 기존 낸드 패키징이 칩을 수평으로 배치하거나 와이어 본딩으로 엉성하게 연결했다면, HBF는 수직 적층(Vertical Stacking)과 TSV(실리콘 관통 전극) 기술을 사용하여 칩 사이에 수천 개의 고속도로(I/O)를 뚫습니다.[4]
구체적으로 살펴보면, 패키지 최하단에는 베이스 로직 다이(Base Logic Die)가 위치합니다. 이 똑똑한 다이는 단순히 데이터를 전달하는 문지기가 아닙니다. 낸드의 고질적인 문제인 에러 정정(ECC)이나 수명 관리(Wear Leveling)를 직접 수행하고, 나아가 일부 연산 기능(PIM)까지 담당하는 지능형 컨트롤러 역할을 합니다. 그 위로 8개에서 16개 이상의 3D 낸드 칩이 수직으로 쌓이며, 병렬 동작을 통해 대역폭을 극대화합니다.
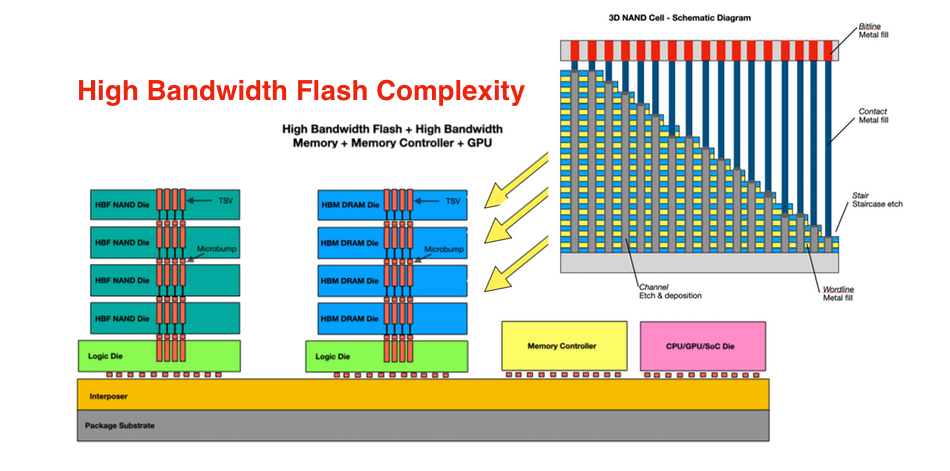
하지만 여기서 중요한 기술적 난제가 발생합니다. 낸드를 이렇게 높게 쌓고 고속으로 동작시키면, 엄청난 열이 발생하고 전력 소모가 급증합니다. 이를 해결하기 위해 필요한 것이 바로 삼성전자가 연구 중인 FeFET(강유전체 트랜지스터)와 같은 근원적인 소자 혁신, 혹은 SK하이닉스가 시도하는 MR-MUF, VFO와 같은 패키징의 마법입니다.[5] HBF는 단순한 빠른 낸드가 아닙니다. 스토리지(Storage)의 영역에 있던 낸드가 메모리의 영역으로 침투하는, 반도체 계층 구조의 혁명적 사건입니다.[6]
그러면 SK하이닉스와 삼성이 각자 어떤 방법을 고수하는지 알아볼까요.
Chapter 3: 연구 결과
SK하이닉스: 생태계 표준화와 패키징의 승부수

SK하이닉스는 HBM 시장에서의 승리에 취해 있기보다 그 다음을 계속 보고 있는데요. 그들은 이미 낸드 기반 AI 솔루션인 AIN (AI-NAND) 브랜드를 런칭하며 시장 선점에 나섰어요. 특히 주목해야 할 것은 AIN-B(Bandwidth)라 불리는 HBF 제품군이라 생각합니다.[7] SK하이닉스의 전략은 “혼자 하지 않는다”로 요약할 수 있습니다.
2025년 8월, SK하이닉스는 웨스턴디지털의 자회사인 샌디스크(SanDisk)와 HBF 기술 표준화를 위한 MOU를 체결했습니다. 이것이 왜 중요할까요? HBF는 새로운 인터페이스를 요구합니다. 엔비디아나 AMD 같은 GPU 제조사 입장에서, 특정 메모리 업체만 사용하는 독자 규격은 리스크입니다. SK하이닉스는 낸드 시장의 강자인 샌디스크와 손잡고 SK의 규격을 업계 표준으로 만들어, GPU 제조사들이 HBF를 채택할 때 겪을 기술적 파편화를 제거하려는 고도의 전략을 구사하고 있습니다. [8]
기술적으로는 HBM에서 검증된 MR-MUF(Mass Reflow-Molded Underfill) 공정을 낸드 적층에도 적용합니다. 칩 사이에 액체 보호재를 주입해 굳히는 이 방식은 열 방출 효율이 뛰어나 HBF의 발열 문제를 제어하는 데 핵심적인 역할을 합니다. 또한, 그들은 VFO(Vertical Fan-Out) 기술을 도입하여 칩 내부에 구멍을 뚫는 TSV 대신, 칩 가장자리를 통해 배선을 연결하는 방식을 연구 중입니다. 이는 TSV 대비 비용이 저렴하고 칩 손상을 최소화하여 수율을 높일 수 있는 획기적인 기술로, 모바일 온디바이스 AI용 HBF 시장까지 노리고 있습니다. SK하이닉스는 2026년 샘플, 2027년 양산을 목표로 속도전을 펼치고 있습니다.[9]
삼성전자: 근원적 물성 혁신, FeFET라는 게임 체인저
반면, 삼성전자의 전략은 더 깊고 근원적입니다. 그들은 당장의 제품 출시보다, 미래의 한계를 돌파할 기반 기술 확보에 집중하고 있습니다. 그 증거가 바로 제가 입수한 삼성전자 SAIT와 반도체연구소의 네이처(Nature) 게재 논문 Ferroelectric transistors for low-power NAND flash memory입니다.[10]

이 논문은 3D 낸드가 적층을 계속 높이면서 피할 수 없게 된 전력 소모 문제를 정면으로 다루는데요. 낸드는 구조상 데이터를 읽을 때 하나의 셀만 선택해 접근할 수 없고, 같은 줄에 연결된 나머지 수천 개의 셀에도 전기가 지나가야 합니다. 이때 선택되지 않은 셀들을 단순히 “통과”시키기 위해 걸어주는 전압이 패스 전압(V_pass)입니다. 적층이 500단, 1,000단으로 높아질수록 이 전압이 걸리는 셀의 수가 기하급수적으로 늘어나고, 읽기 동작만으로도 막대한 전력이 소모되는 구조적 한계가 발생합니다.
기존 낸드는 전하를 절연층에 가둬 상태를 구분하는 전하 포획(CTF) 방식이기 때문에, 셀의 열림과 닫힘을 확실히 구분하려면 비교적 높은 전압을 유지할 수밖에 없었습니다. 이 때문에 V_pass를 낮추는 데 근본적인 제약이 있었습니다. 삼성 연구팀은 이 지점을 정면으로 바꿨습니다. 누설 전류가 거의 없는 IGZO 채널과, 짧은 전압 인가만으로도 상태가 유지되는 강유전체(HZO) 게이트를 결합한 새로운 소자를 도입한 것입니다.
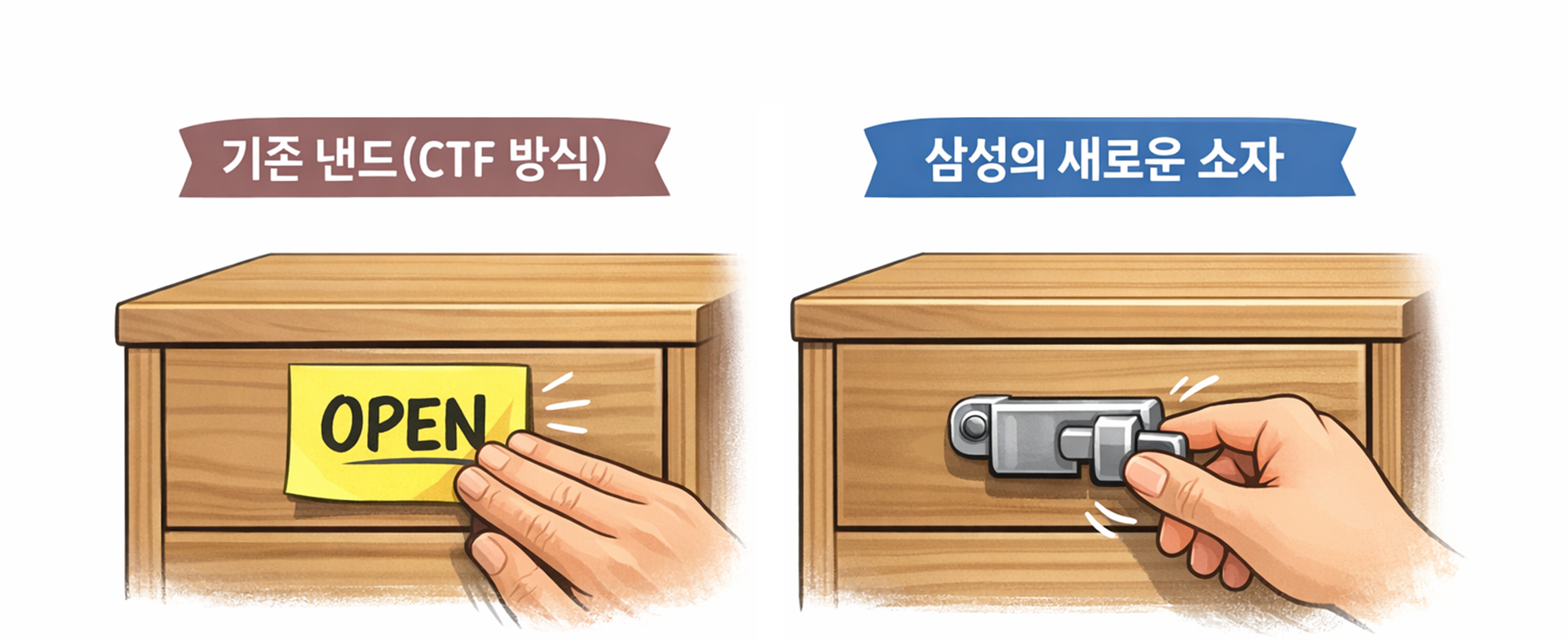
비유해서 설명하면, 기존 낸드(CTF 방식)는 스티커로 표시된 서랍과 같습니다. 서랍이 열렸는지 닫혔는지를 보려면, 스티커가 제대로 붙어 있는지 확인해야 합니다. 문제는 이 스티커가 조금만 약하면 떨어지진다는 점입니다. 그래서 항상 강하게 눌러 붙여야 합니다. 높은 전압이 필요한 거죠. 그래서 V_pass를 쉽게 낮출 수 없었습니다. 삼성 연구팀이 바꾼 건 스티커가 아니라 서랍의 잠금장치입니다. 스티커를 세게 붙이지 않아도, 서랍 손잡이만 살짝 움직여 보면 열렸는지 닫혔는지가 분명하게 느껴집니다. 아주 작은 힘만 줘도 상태가 유지되고, 헷갈리지 않습니다. 이게 IGZO와 강유전체를 썼다는 말의 의미입니다.
이 구조의 핵심은 “통과시키기 위해 굳이 전기를 쓰지 않아도 된다”는 점입니다. IGZO의 낮은 누설 특성을 활용해, 비선택 셀에 걸리는 V_pass를 0V에 가깝게 낮추는 데 성공했고, 그 결과 스트링 동작 시 전력 소모를 기존 CTF 방식 대비 96%까지 줄였습니다. 이는 효율을 조금 개선한 수준이 아니라, 읽기 동작에서 발생하던 전력 낭비 자체를 구조적으로 제거했다는 의미입니다.
전력 소모가 이 정도로 줄어들면, 같은 전력 예산 안에서 더 많은 낸드를 쌓을 수 있고, 발열 제약 때문에 묶여 있던 동작 속도도 풀리게 됩니다. 실제로 연구팀은 낮은 전압 환경에서도 셀 상태를 안정적으로 구분할 수 있는 메모리 윈도우를 확보했고, 셀 하나에 32가지 상태를 담는 5-bit 동작 가능성까지 입증했습니다. 즉, 더 높게 쌓고, 더 많이 담으면서도, 전기는 훨씬 덜 쓰는 방향이 열렸다는 뜻입니다.

삼성전자는 이와 함께 2025년 하반기 양산될 V10 낸드부터 하이브리드 본딩(Hybrid Bonding)을 도입합니다. 구리와 구리를 직접 붙이는 이 기술은 칩 두께를 획기적으로 줄여, HBF 구현을 위한 물리적 높이 제한을 극복하는 필수 열쇠가 될 것입니다.[11]
자세한 내용은, “삼성과 하이닉스의 HBM4E 전쟁, 어디에 투자해야 할까?” 리포트를 통해 확인하실 수 있습니다.
FeNAND의 두 얼굴: 저전력 스토리지 vs 아날로그 연산기
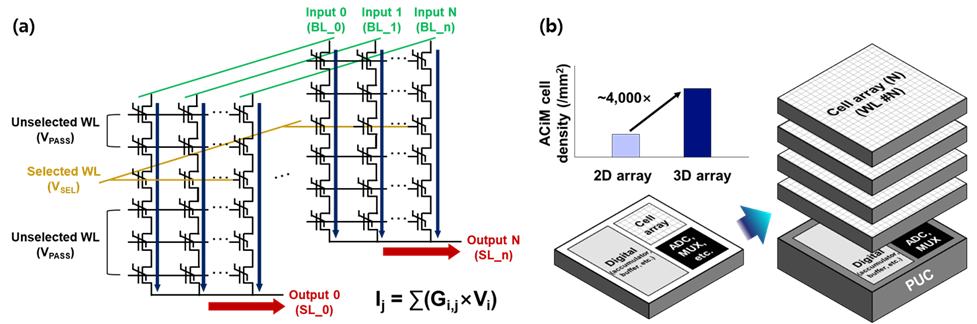
흥미로운 점은 SK하이닉스 역시 3D 강유전체 메모리(FeNAND)를 연구하고 있다는 것입니다. IEDM 2024에서 발표된 SK하이닉스의 논문에 따르면, FeNAND를 아날로그 연산기로 활용하려 합니다. [12] 지금의 CPU, GPU는 디지털 계산기입니다. 숫자를 0과 1로 바꾼 다음, 곱하고, 더하고, 다시 저장합니다.
AI에서 이 과정은 “데이터를 메모리에서 꺼낸다 → 연산 칩으로 보낸다 → 곱하고 더한다 → 다시 메모리에 쓴다.”가 계속 반복되고 시간과 전기를 많이 잡아 먹습니다. 계산 그 자체보다, 왔다 갔다가 더 비싼 거죠. 아날로그 연산에서는 숫자를 굳이 0과 1로 바꾸지 않습니다. 전압의 크기, 전류의 세기 같은 물리량 자체가 숫자 역할을 합니다. 우리가 따로 “곱해라”, “더해라”라고 명령할 필요가 없습니다. 회로가 알아서 계산을 끝냅니다.
AI 연산의 대부분은 아주 단순합니다. 숫자를 곱하고, 그 결과를 계속 더하는 거잖아요? 아날로그 방식에서는 덧셈은 전류가 합쳐지면서 자동으로 끝납니다. 수천 개의 곱셈이 동시에 일어나고 덧셈은 전류가 합쳐지면서 자동으로 끝납니다. 그래서 같은 면적, 같은 시간에 처리할 수 있는 계산량이 차원이 달라집니다. 물론 정확성이 좀 떨어진다는 게 문제입니다. 잡음도 심하고 온도에도 민감하죠.
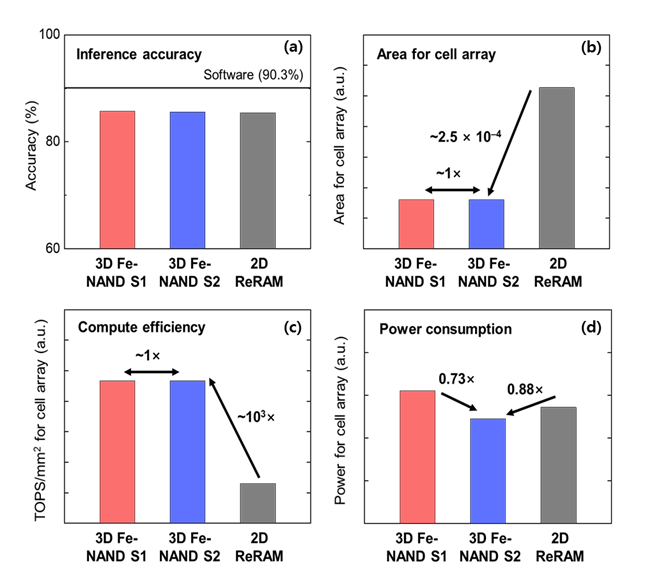
더 구체적으로 말하면, SK하이닉스는 메모리 셀 내부의 전도도(Conductance)를 조절하여 AI의 핵심인 MAC(Multiply-Accumulate) 연산을 메모리 안에서 직접 수행하려는 겁니다. AI 연산은 숫자를 곱하고 더하고를 계속 반복하는 건데, 이걸 MAC 연산이라고 해요. 기존 구조에서는 이 계산을 위해 데이터가 메모리와 연산 칩 사이를 끊임없이 오가야 합니다. 실제로 SK하이닉스가 IEDM에서 발표한 실험 결과에 따르면, 이 방식은 기존 2D 메모리 어레이 대비 집적도에서 약 4,000배, 단위 면적당 연산 성능(TOPS/mm²)에서는 약 1,000배 높은 효율을 기록했습니다[12]. 이는 단순한 성능 개선이 아니라, 연산을 위해 데이터를 이동시키는 구조 자체를 제거했을 때 얻을 수 있는 물리적 이점이 수치로 확인됐다는 의미입니다.
삼성전자는 FeFET를 이용해 전기를 덜 먹는 초고용량 저장 장치를 만들려고 하고 있어요. FeFET은 데이터를 저장할 때 전기를 거의 쓰지 않아도 상태가 유지되는 메모리인데요. FeFET은 전압을 잠깐만 해도 셀의 상태가 고정되기 때문에, 데이터를 저장하고 유지하는 과정에서 반복적으로 전기를 소모하지 않습니다. 삼성이 하고자 하는 건, 같은 전력 예산 안에서 더 많은 낸드를 쌓아 초고용량이면서도 발열과 전력 부담이 낮은 HBF를 구현하는 겁니다.
이 흐름을 보면, 2030년 전후 HBF 시장은 두 갈래로 나뉠 가능성이 큽니다. 삼성전자의 FeFET 기반 HBF는 전력 소모를 최소화한 초고용량 메모리로 데이터센터의 운영 비용을 낮추는 역할을 맡게 될 것이고, SK하이닉스의 연산형 HBF는 데이터 이동 없이 추론을 수행하는 메모리로 진화할 가능성이 있습니다. 지금은 두 회사가 서로 다른 방향에서 접근하고 있지만, 두 기술이 만나는 지점에서 AI 메모리 구조는 다시 한 번 크게 바뀌게 되겠죠.
비유하자면 삼성전자 FeFET기반 HBF라는 건 아주 큰 창고인데, 이 창고의 특징은 전기료가 거의 안 든다는 겁니다. 데이터센터에서 제일 돈이 많이 나가는게 데이터를 많이 저장하고 그걸 켜두는 건데, 삼성의 HBF는 데이터를 많이 담아두고 오래 유지하는데 전기는 적게 먹습니다. SK하이닉스는 창고이면서 작업장입니다. 보통은 창고에서 물건을 꺼내서 작업장으로 옮긴 다음 거기서 계산을 하는데요. 하이닉스는 꺼내서 옮기지 않고 창고 안에서 바로 계산을 합니다. AI에서 가장 많이 하는 단순 계산을 빠르게 끝내버리는 거죠. 둘의 차이를 한 문장으로 정리하면 하이닉스는 들고 있는 데이터를 그 자리에서 처리하고 삼성은 데이터를 싸게 많이 들고 있다고 보면 됩니다.
어디가 승자가 될 지는 그 누구도 아직 모릅니다. 선택은 여러분의 몫이죠.
Chapter 4: 앞으로의 미래
당장 시장이 요구하는 속도와 표준은 SK하이닉스가 앞서 있습니다. 샌디스크(SanDisk)와의 동맹을 통해 HBF 인터페이스 표준을 장악하고, 검증된 패키징 기술(MR-MUF)로 엔비디아와 같은 빅테크의 즉각적인 수요를 독점할 것입니다. 이는 한국이 초기 HBF 시장의 Rule Setter가 됨을 의미합니다.
하지만 낸드 적층이 500단을 넘고 1,000단(2030년 목표)을 향해 갈 때, SK하이닉스는 열적 한계(Thermal Wall)에 봉착할 것입니다. 16단 이상 쌓은 HBF가 뿜어내는 열은 MR-MUF 패키징만으로는 감당할 수 없습니다. 이때 전력 소모를 소자 레벨에서 96% 줄인 삼성의 FeFET 기술이 빛을 발할 것입니다. 데이터 센터가 발열과 전력난에 허덕일 때, 구원투수는 삼성전자가 될 것입니다. 전력 소모를 96%나 줄인 FeFET 소자 혁신은 단순한 개선이 아니라, 물리학적 한계를 깨부순 수준이거든요.
AI 데이터 센터 하나가 도시 하나의 전력을 소비하는 시대입니다. 전기를 덜 먹는 칩이 곧 국방력인 시대가 도래했습니다. 만약 한국 기업들이 이 저전력 메모리 기술(FeFET, Analog Compute FeNAND)을 완성하지 못하면 구글, 애플, 메타, 테슬라 같은 빅테크들이 자체 칩을 만들어 우리를 하청 업체로 전락시키겠지요.
단순히 기업 간의 점유율 싸움이 아닙니다. 폭증하는 AI 전력 소모로 지구가 끓고 있는 지금, 에너지를 통제하는 자가 AI 패권을 쥐게 됩니다. SK는 길을 닦고 있고, 삼성은 그 길 위를 달릴 자동차의 엔진을 바꾸고 있습니다.
연구자 의견
지금 투자 가치가 있는가?
네, 있습니다. SK하이닉스의 주가는 HBM의 날개를 달고 고공 행진 중이고, 삼성전자는 겨울이 왔다는 조롱 섞인 비관론에 갇혀 있습니다. 하지만 현업자들의 시각은 조금 다릅니다. 좀 오글거리고 거칠게 표현하자면, SK하이닉스는 현재의 AI 속도전을 위한 가장 확실한 무기를 팔고 있고, 삼성전자는 인류가 직면할 열(Heat)의 종말을 막아낼 입장권을 설계하고 있다고 봅니다.
먼저 두 기업에 점수를 매겨보겠습니다. SK하이닉스는 실행력 면에서 100점 만점에 95점입니다. 샌디스크와의 동맹과 MR-MUF 패키징은 당장 돈이 되는 기술입니다. 반면 삼성전자는 잠재력 면에서 90점입니다. 지금은 수율 문제로 욕을 먹고 있지만, Nature에 게재된 FeFET 기술은 경쟁자가 흉내 낼 수 없는 영역입니다.
단순히 반도체 잘 만드는 회사가 아니라, 왜 이들이 AI 시대의 산소 호흡기이자 엔진이 될 수밖에 없는지, 그들이 구축한 진짜 해자가 무엇인지 말씀드려보겠습니다.
1. SK하이닉스는 왜 표준에 집착할까?
많은 분들이 묻습니다. NAND 쌓는 게 뭐 그리 대수냐? 중국 YMTC도 200단 쌓는데 금방 따라잡는 거 아니냐?
결론부터 말하면, HBF 시장에서는 불가능합니다. HBF는 단순한 저장 창고가 아니라, GPU와 대화하는 생태계이기 때문입니다.
SK하이닉스가 SanDisk(웨스턴디지털)와 손잡고 기술 규격 표준화를 주도한 것은 신의 한 수입니다. 이는 마치 레고 블록의 결합 규격을 선점한 것과 같습니다. 엔비디아나 AMD가 이들이 만든 SK-SanDisk 표준에 맞춰 GPU를 설계하기 시작하면, 후발 주자가 아무리 높게 쌓은 칩을 가져와도 꽂을 구멍이 맞지 않게 됩니다. SK하이닉스가 마주한 벽은 이제 기술이 아니라 시장 장악력이며, 그들은 이미 그 벽을 넘어 Rule Setter가 되었습니다.
2. 진짜 해자는 높이가 아니라 전압에 있다
대중은 HBF를 누가 더 높이 쌓느냐(Stacking)의 싸움으로 압니다. 하지만 전문가가 보는 삼성전자의 소름 돋는 무기는 따로 있습니다. 바로 V_pass 제로화 기술입니다.
1,000단짜리 아파트를 지었다고 칩시다. 1층에 갈 때마다 1,000층 전체에 불을 켜야 한다면 전기세 때문에 그 아파트는 망합니다. 이게 현재 낸드 기술의 치명적 한계입니다. 여기서 필요한 게 삼성전자의 FeFET(강유전체) 기술입니다
IGZO (누설 전류 차단): 수도꼭지를 잠가도 물이 새는 실리콘과 달리, 산화물 반도체(IGZO)는 물 한 방울도 새지 않게 잠급니다
FeFET (전압 기억): 전기를 끊어도 상태를 기억합니다. 덕분에 불필요한 층에 전기를 흘려줄 필요가 없습니다.
문제는 이 소재를 다루는 것이 살얼음판이라는 겁니다. 산화물은 공정 중에 조금만 다쳐도 특성이 변하니까요. 삼성은 이 예민한 소재를 3D 수직 구조에 구현해 냈고, 경쟁사들이 넘볼 수 없는 소재 물성의 장벽을 세웠습니다.
3. 열의 벽을 넘는 냉각 본능
기존 방식의 치명적인 단점은 발열이었습니다. 칩을 높이 쌓을수록 열이 빠져나갈 곳이 없어 성능을 강제로 낮춰야(Throttling) 했습니다. SK하이닉스는 이 문제를 패키징(MR-MUF)이라는 외부적인 방법으로 풀었고, 삼성전자는 소자(FeFET)라는 내부적인 방법으로 풀었습니다.
SK의 접근: “열이 나면 잘 식히자.” 액체 보호재를 써서 열을 빼냅니다. 당장 양산하기에 가장 현실적이고 빠른 해법입니다
삼성의 접근: “애초에 열이 안 나게 하자.” 전력 소모를 96% 줄여버리면 발열 자체가 사라집니다.
단기적으로는 잘 식히는 SK가 이기겠지만, 칩이 더 뜨거워지는 미래에는 애초에 열을 안 내는 소자의 중요성이 강조됩니다.
4. 결론: 한국의 양날개 전략은 옳았다
AI 시대, 데이터의 양이 폭증할수록 속도와 전력 효율은 타협할 수 없는 가치가 됩니다. 이제 싸움은 누가 더 빨리 만드느냐는 SK하이닉스가, 누가 더 효율적으로 만드느냐는 삼성전자가 맡고 있습니다.
만약 제가 1억 을 태운다면, 40%는 당장의 현금 흐름을 지배할 SK하이닉스에, 60%는 미래의 에너지 패권을 쥘 삼성전자에 넣겠습니다. 삼성의 기술이 상용화되는 2028년, 이 기술은 단순한 메모리가 아니라 데이터 센터의 전기세를 반으로 줄여주는 에너지 솔루션이 될 것입니다. 따라서 두 기업 모두 현재 기술적으로 강력한 매수 가치가 있습니다.